
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- set시간복잡도
- 공공빅데이터청년인턴
- 행별속성합계
- 셋
- 파이썬셋
- 작업형2
- 2회기출
- 리스트
- 파이썬튜플
- 파이썬입출력
- 빅데이터분석기사
- 워드클라우드
- csv병합
- 파이썬딕셔너리
- 공빅데
- 빅분기
- 공빅데기관매칭
- 예측모델링
- dataq
- 실기
- 딕셔너리
- 백준 2164
- 빅분기실기
- konlpy
- 컨테이너
- 백준1920
- 파이썬AHP
- 파이썬
- 태블로
- 튜플
- Today
- Total
Data Science
[태블로] [DAY3] (2) 매개 변수, 대시보드 동작 본문

1. 매개 변수를 사용하여 측정값 변경하기1 & 마크 색상 표현하기
(1) 하나의 시각화에서 여러 개의 측정값을 비교해보고,
(2) 선택한 카페인 함유량에 따라서 카테고리 색상이 표시되도록 합니다.
먼저, 매개변수를 추가합니다.
만든 매개변수를 이용하기 위해서 계산된 필드 '선택한 측정값'을 만들어봅시다.
이전에는 CASE-WHEN 구문을 사용했다면, 이번엔 IF-ELSEIF 구문을 사용해봅니다.
위의 결과는 합계로 집계됩니다.
카테고리 별로 분석하는 것이니 집계형태를 평균으로 바꿔야겠죠?
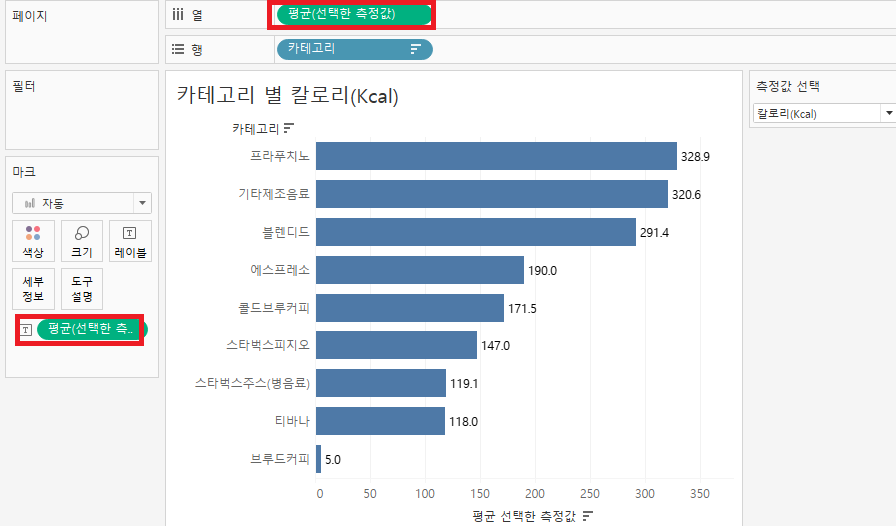
이제 카페인 함유량에 따라서 색상을 표현하겠습니다.
매개변수를 추가해줍니다.
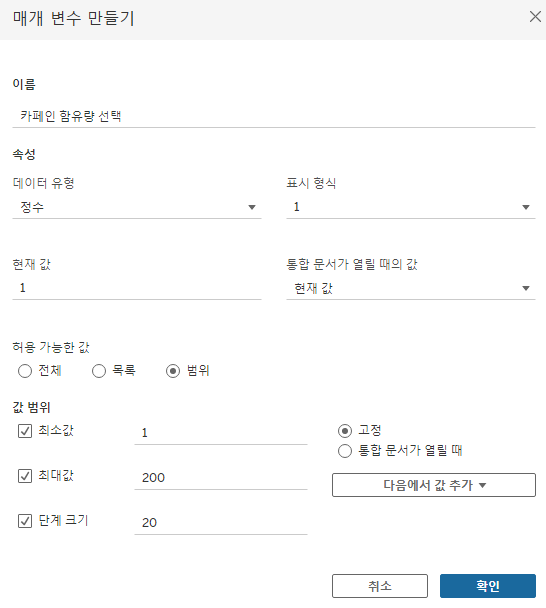
만든 매개변수를 이용하기 위해서 계산된 필드 '카페인 > 선택한 카페인'을 만들어봅시다.

'카페인 > 선택한 카페인' 필드를 마크-색상에 놓아줍니다
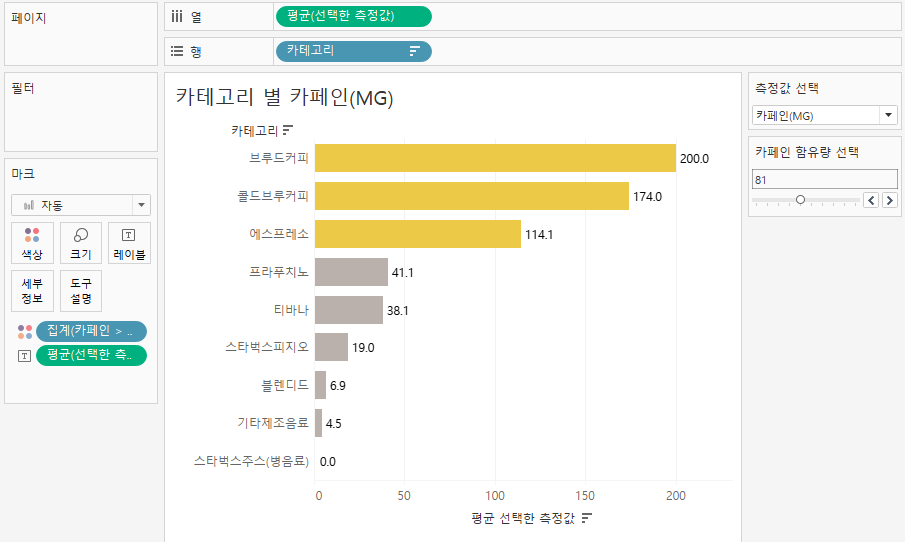
위와 같이 카페인이 81 초과인 것에 색상이 잘 적용됐습니다.
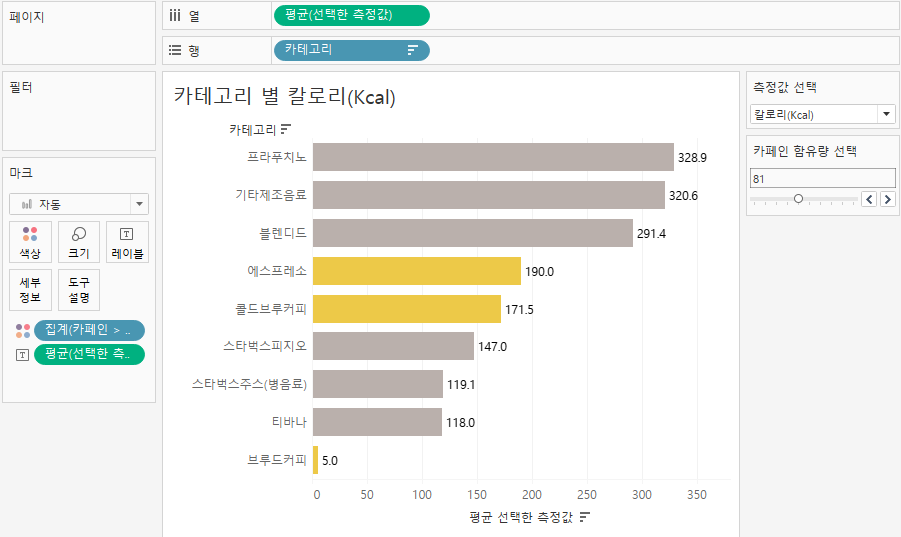
칼로리 별로 정렬하고, 카페인 81 초과를 필터링 해봤습니다.
프라푸치노는 칼로리가 높지만, 카페인은 적고
브루드커피는 칼로리가 낮지만, 카페인은 높음을 알수있어요.
2. 매개 변수를 사용하여 측정값 변경하기2
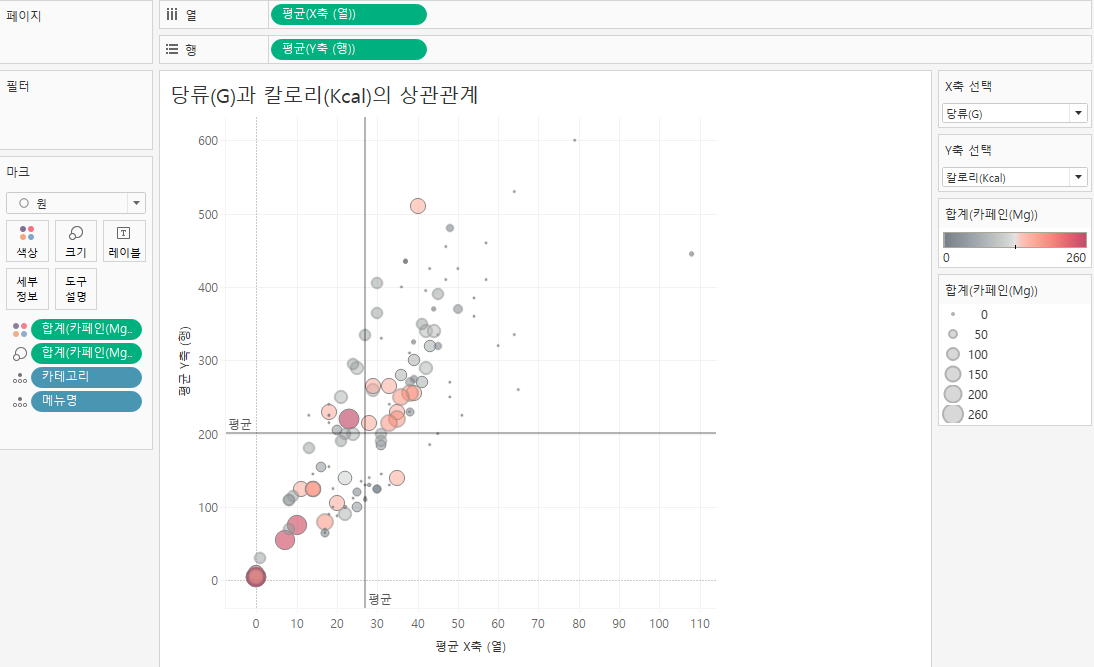
선택한 측정값에 따라서 두 측정값의 상관 관계를 살펴보는 동적 시각화를 만들어 봅시다.
eg) 당류와 칼로리의 상관관계
먼저, X축과 Y축에 들어갈 매개변수를 생성해줍니다.
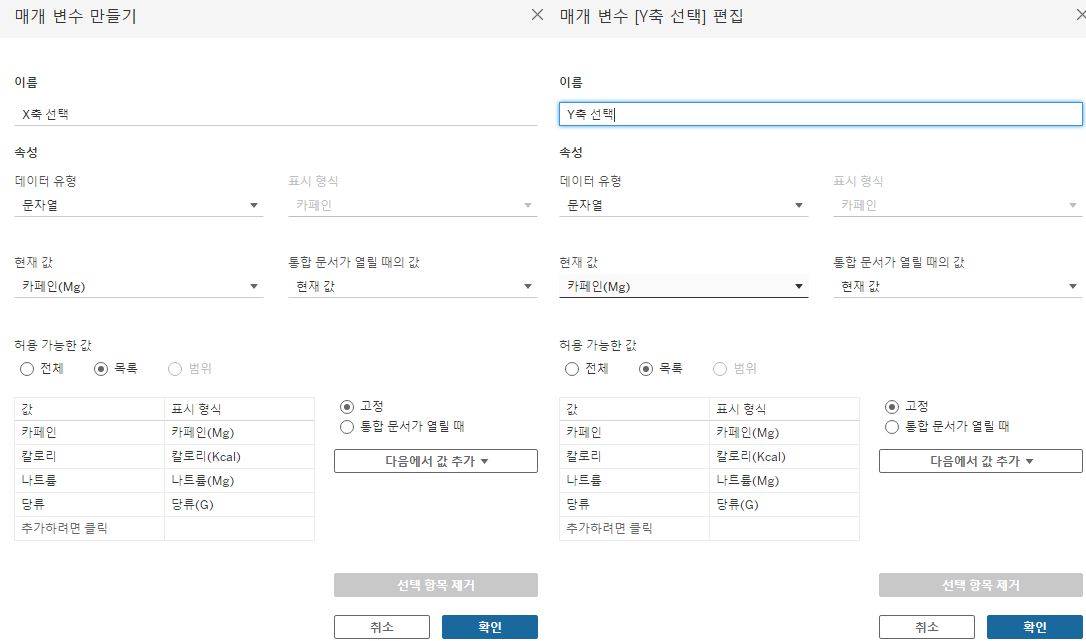
만든 매개변수를 이용하기 위해서 계산된 필드 'X,Y 축'을 만들어봅시다.

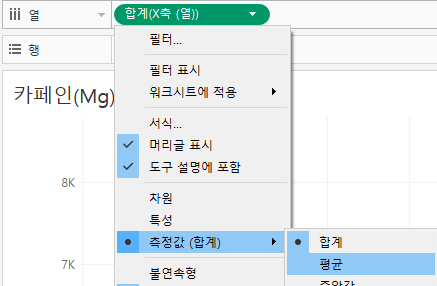
집계 형태를 합계->평균으로 바꾸는 것도 놓치지 마세요!
(이렇게 싫으면, 계산식에서 AVG([카페인(Mg)])로 작성하면 됩니다.)
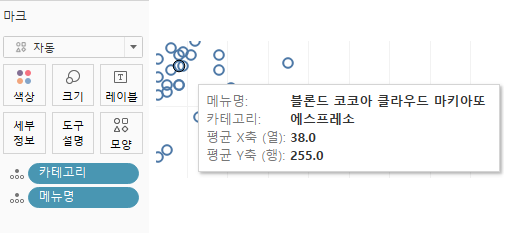
세부정보에 카테고리와 메뉴명을 넣습니다.
마우스 오버하면 정보를 볼수있습니다.
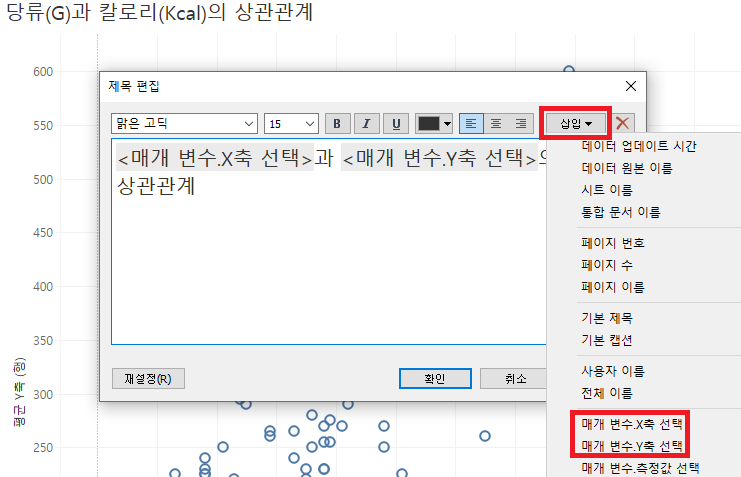
제목도 동적으로 변해요.
제 경우에는 자동으로 안되어서 직접 수정했습니다
분석 탭에서 평균라인도 넣고,
카페인 양에따라 크기와 색상도 설정합니다.
3. 대시보드 작업 적용하기
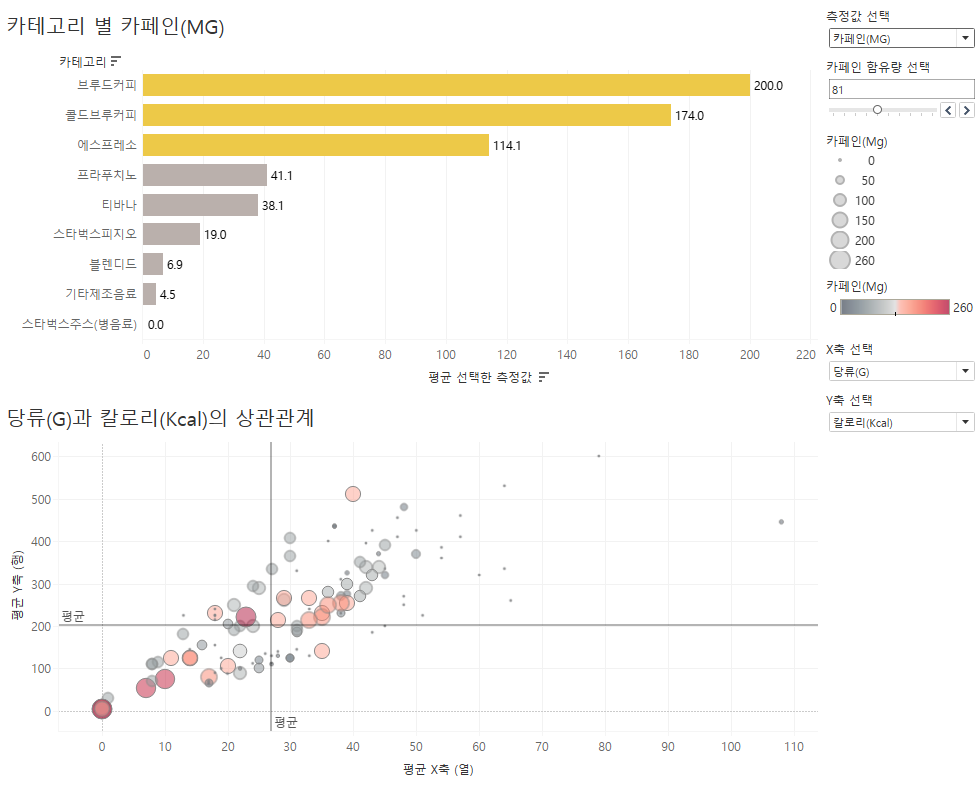
1,2 번 분석을 이용해서 대시보드를 만들고, '대시보드 동작'을 이용해 해당 카테고리 별 제품을 '하이라이트' 해봅시다.
먼저, 만들어진 대시보드입니다.
대시보드 동작을 추가하겠습니다.
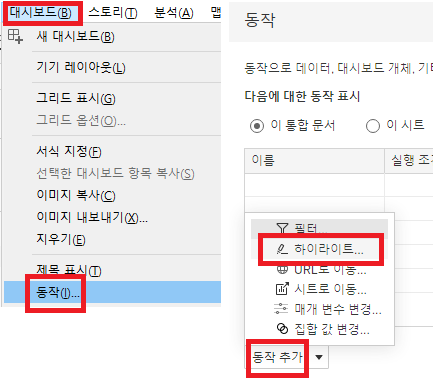
원본시트와, 대상시트를 잘 구분해야합니다.
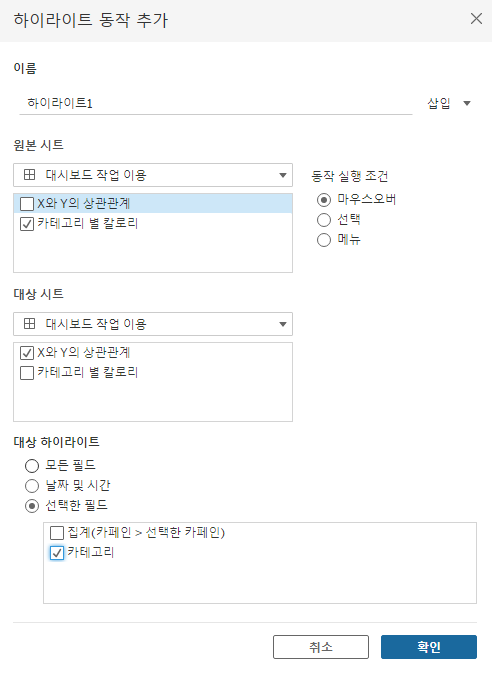
대상 하이라이트에는 '카테고리'를 선택합니다.
만약 대상 시트에 하이라이트 되는 필드가 없다면, 무엇을 하이라이트를 해야하는지 모르니 작동하지 않습니다.
때문에 세부정보에서 '카테고리'를 미리 추가해둔것입니다.
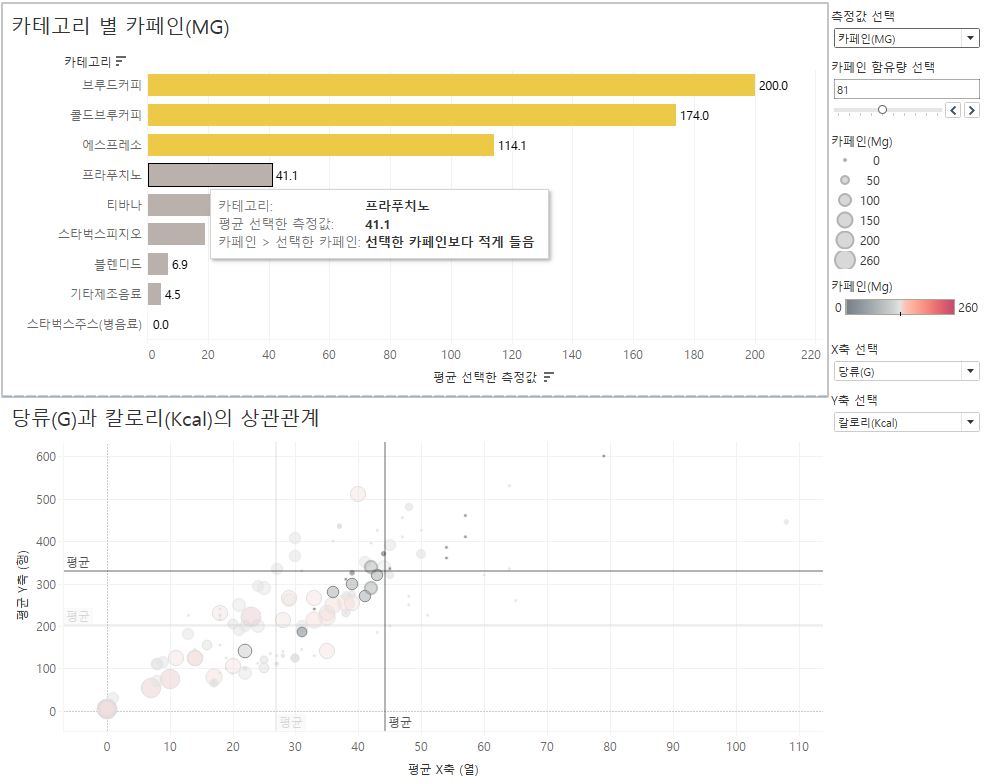
마우스오버를 하면 해당 카테고리에 맞는 데이터를 하이라이트 해줍니다.
'데이터분석' 카테고리의 다른 글
| [태블로] [DAY4] 테이블 계산식, 시간 분석, 덤벨 차트 (1) | 2023.06.08 |
|---|---|
| [태블로] [DAY3] (1) 매개 변수, 대시보드 동작 (0) | 2023.06.07 |
| [태블로] [DAY2] 행과 집계, 필드계산 (0) | 2023.06.06 |
| [태블로] [DAY1] 카테고리별 메뉴 분석 (0) | 2023.06.06 |
| [태블로] [DAY0] 기초실습교육 (1) | 2023.06.06 |



