
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 실기
- 파이썬딕셔너리
- 파이썬AHP
- 행별속성합계
- 빅분기실기
- 컨테이너
- dataq
- 작업형2
- konlpy
- csv병합
- 튜플
- set시간복잡도
- 파이썬튜플
- 예측모델링
- 빅분기
- 2회기출
- 워드클라우드
- 리스트
- 빅데이터분석기사
- 파이썬입출력
- 파이썬
- 파이썬셋
- 공빅데기관매칭
- 백준1920
- 백준 2164
- 공빅데
- 태블로
- 공공빅데이터청년인턴
- 셋
- 딕셔너리
- Today
- Total
Data Science
[빅분기] 실기 단답형 100제 본문
문제1. 확률변수가 기댓값으로부터 얼마나 떨어진 곳에 분포하는지 가늠하는 숫자는 무엇인가요?
답: 분산
문제2. 인공신경망의 출력값이 원하는 결과와 다를 경우, 가중치 갱신을 통해 오차를 최소화 시키도록 반복수행하여 신경망을 학습시키는 알고리즘이 무엇인가요 ?
답: 역전파 알고리즘
문제3. 차원축소와 군집화를 동시에 수행하며, 고차원으로 표현된 데이터를 저차원으로 변환하여 보는 비지도학습 기반 클러스터링 기법은 무엇인가요 ?
답: 자기 조직화 지도(self organization map) - SOM
문제4. 많은 데이터를 그림을 이용하여 집합의 범위와 중앙값을 빠르게 확인할 수 있으며, 또한 통계적으로 이상값이 있는지 빠르게 확인이 가능한 시각화 기법은 무엇인가요 ?
답: 박스플롯
문제5. 학습 데이터에 대한 성능은 좋지만 실제 데이터에 대해 성능이 떨어지는 현상을 무엇이라고 하나요 ?
답: 과대적합(over fitting)
문제6. 모델 내부에서 확인이 가능한 변수로 데이터를 통해서 산출이 가능한 값이며 예측을 수행할 때 모델에 요구되어지는 값들을 무엇이라 하나요? 예를 들어 인공신경망에서의 가중치, 서포트 벡터 머신에서의 서포트 벡터를 말합니다.
답: 파라미터(parameter)
문제7. 모델에서 외적인 요소로 데이터 분석을 통해 얻어지는 값이 아니라 사용자가 직접 설정해주는 값이고 경험에 의해 결정가능한 값은 무엇인가요 ?
답: 하이퍼 파라미터(Hyper-Prameter)
문제8. 실제 분류 범주를 정확하게 예측한 비율을 무엇이라 하나요 ?
답: 정확도
문제9. 모델 평가의 이원교차표에서 '참' 으로 예측한 비율중에서 실제로 '참' 인 비율을 무엇이라고 하나요?
답: 정밀도
문제10. 모델 평가의 이원교차표에서 실제 참을 참으로 분류한 비율을 무엇이라 하나요 ?
답: 재현율

문제11. 이것은 모집단에 대한 가설이 가지는 통계적 의미를 말하는 것으로 어떤 실험 결과 자료를 두고 '통계적으로 유의하다' 라고 하는 것은 확률적으로 봐서 의미가 있다는 뜻을 무엇이라고 하나요 ?
답: 통계적 유의성
문제12. 회귀분석에서 회귀모형이 얼마나 잘 설명하고 있는지를 보여주는 지표로 회귀선의 정확로를 평가할 때 사용하며 전체 제곱합에서 회귀 제곱합의 비율을 나타내는 지표를 무엇이라고 하나요 ?
답: 결정계수
문제13. 모집단 분산이 서로 동일하다고 가정되는 두 모집단으로 부터, 표본 크기가 각각 n1, n2 인 독립적인 2개의 표본을 추출하였을 때, 2개의 표본 분산 s1^2, s2^2 의 비율을 무엇이라고 하나요 ?
답: F-통계량
문제14. 예측을 통해 설명이 되는 결과적인 변수를 무엇이라고 하나요 ?
답: 반응변수, 결과변수, 목적변수, 종속변수
문제15. 머신러닝 모델 의사결정트리에서 불순도를 측정하는 척도로 무질서한 정도를 나타내는 척도가 무엇인가요 ?
답: 엔트로피
문제16. 학습 알고리즘에서 잘못된 가정을 했을때 발생하는 오차를 무엇이라고 하나요 ?
답: 편향(Bias)
문제17. 인공신경망 모델에서 입력신호의 총합을 출력신호로 변환하는 함수로, 입력받은 신호를 얼마나 출력할지를 결정하고 다음 단계에서 출력된 신호의 활성화 여부를 결정하는 함수가 무엇인가요
답: 활성화 함수(activation function)
문제18. 모든 그룹의 공분산 행렬은 같다고 가정하에 관측치로 부터 그룹 중심(평군)까지의 거리 제곱이 최소일 경우 해당 관측치는 해당 그룹으로 분류하는 분석을 무엇이라고 하나요 ?
답: 선형판별분석
문제19. 저차원에서 함수의 계산만으로 원하는 풀이가 가능한 커널함수를 이용하여 고차원 공간으로 매핑할 경우에 증가하는 연산량의 문제를 해결하는 기법은 무엇인가요?
답: 커널트릭(kernel Trick)
문제20. 머신러닝 연관성 분석에서 전체 거래중 항목 A 와 항목 B 를 동시에 포함하는 거래의 비율을 무엇이라 하나요 ?
답: 지지도(support)
문제21. 머신러닝 연관성 분석에서 A 상품을 샀을때 B 상품을 살 조건부 확률에 대한 척도를 무엇이라 하나요 ?
답: 신뢰도 (confidence)
문제22. 머신러닝 연관성 분석에서 규칙이 우연에 의해 발생한 것인지 판단하기 위해 연관성의 정도를 측정하는 척도를 무엇이라 하나요 ?
답: 향상도(lift)
문제23. 군집간의 거리계산의 연속형 변수 거리를 측정하는 계산법으로 두 점간의 차를 제곱하여 모든 더한 값의 양의 제곱근을 무엇이라 하나요 ?
답: 유클리드 거리
문제24. 군집간의 거리계산에서 연속형 변수 거리를 측정하는 계산법으로 두 점 간 차의 절대값을 합한값을 무엇이라고 하나요 ?
답 : 맨하튼 거리
문제25. 군집간의 거리계산중 명목형 변수 거리를 측정하는 계산법으로 두 집합사이의 유사도를 측정하는 방법으로 두 집합의 교집합을 두 집합의 합집합으로 나눈 값을 무엇이라 하나요 ?
답: 자카드 계수
문제26. 어떤 시행의 결과가 주어졌다고 할 때, 주어진 가설이 참이라면 그 결과가 나오는 정도를 무엇이라고 하나요 ?
답: 우도(likelyhood)
문제27. 어떤 모수가 주어졌을때, 원하는 값들이 나올 가능도를 최대로 만드는 모수를 선택하는 방법으로 점 추정방식에 속하는 방식을 무엇이라고 하나요 ?
답: 최대 가능도(maximum likelihood)
문제28. 특정 사건이 발생할 확률과 그 사건이 발생하지 않을 확률의 비를 무엇이라고 하나요 ?
답: 승산(odds) / 오즈비
문제29. 교차분석의 검정 방법으로 편차의 제곱값을 기대 빈도로 나눈 값들의 합을 무엇이라고 하나요 ?
답: 카이제곱 검정
문제30. 표본집단의 분포가 주어진 특정 이론을 따르고 있는지를 검정하는 기법을 무엇이라고 하나요 ?
답: 적합도 검정
문제31. 현재까지 주장되어 온 것 또는 기존과 비교하여 변화 혹은 차이가 없음을 나타내는 가설을 무엇이라고 하나요?
답: 귀무가설
문제32. 여러 범주를 가지는 2개의 요인이 독립적인지, 서로 연관성이 있는지를 검정하는 기법을 무엇이라고 하나요 ?
답: 독립성 검정
문제33. 대립가설이 맞을 때 그것을 받아들이는 확률을 무엇이라고 하나요 ?
답: 기각역
문제34. 어떤 가설이 통계적으로 유의한지 아닌지 결정하는 행위를 무엇이라고 하나요 ?
답: 검정(test)
문제35. 두 변수가 서로 독립일 경우에 이론적으로 기대할 수 있는 빈도 분포로 두 변수 사이에 연관성이 없다는 가정하에 예상되는 빈도를 무엇이라고 하나요 ?
답: 기대빈도
문제36. 상관관계가 있는 고차원 자료를 자료의 변동을 최대한 보존하는 저차원 자료로 변환하는 차원축소 방법을 무엇이라고 하나요 ?
답: 주성분 분석 (PCA)
문제37. 연도별, 분기별, 월별 등 시계열로 관측되는 자료를 분석하여 미래를 예측하기 위한 분석 기법을 무엇이라고 하나요?
답: 시계열 분석
문제38. 참값과 근사값의 차이로 근사값에서 참값을 뺀 값을 무엇이라고 하나요 ?
답: 오차
문제39. 통계에서 조사 내용으로서의 특성 수량을 나타낸 값을 무엇이라고 하나요 ?
답: 변량
문제40. 두가지 사건 사이에 연관성이 존재하는 상태임을 나타내는 척도가 무엇인가요?
답: 상관관계
문제41. 손실 함수의 기울기를 구하여, 그 기울기를 따라 조금씩 아래로 내려가 최종적으로는 손실 함수가 가장 작은 지점에 도달하도록 하는 알고리즘을 무엇이라 하나요 ?
답: 확률적 경사하강법
문제42. 인간이 이해할 수 있는 언어를 기계가 이해할 수 있게 하는 기술을 무엇이라 하나요 ?
답: 자연어 처리
문제43. 여러가지 동일한 종류 또는 서로 상이한 모형들의 예측/분류 결과를 종합하여 최종적인 의사결정에 활용하는 기법을 무엇이라 하나요 ?
답: 앙상블 기법
문제44. 앙상블 기법으로 학습 데이터에서 다수의 부트스트랩 자료를 생성하고 각 자료를 모델링한 후 결합하여 최종 예측 모형을 만드는 알고리즘을 무엇이라 하나요 ?
답: 배깅(baggnig)
문제45. 앙상블 기법으로 잘못 분류된 개체들에 가중치를 적용하여 새로운 분류 규칙을 만들고 이 과정을 반복해 최종 모형을 만드는 알고리즘을 무엇이라 하나요 ?
답: 부스팅(boosting)
문제46. 의사결정나무의 특징인 분산이 크다는 점을 고려하여 배깅과 부스팅보다 더 많은 무작위성을 주어 약한 학습기들을 생성한수 이를 선형 결합하여 최종 학습기를 만드는 방법을 무엇이라 하나요 ?
답: 랜덤 포레스트(random forest)
문제47. 평균이나 분산과 같은 모집단의 분포에 대한 모수성을 가정하지 않고 분석하는 통계적 방법을 무엇이라 하나요?
답: 비모수 통계
문제48. 모집단 분포 특성을 규정짓는 척도 및 모집단의 특성치를 무엇이라 하나요 ?
답: 모수
문제49. 모집단에 대한 통계적 가설을 세우고 표본을 추출한 다음, 그 표본을 통해 얻은 정보를 이용하여 통계적 가설의 진위를 판단하는 검정방법을 무엇이라 하나요 ?
답: 가설검정
문제50. 분석모델에서 구한 분류의 예측범주와 데이터의 실제 분류 범주를 교차표 형태로 정리한 행렬을 무엇이라 하나요?
답: 혼동행렬
문제51. 실제 긍정(관심범주)인것중에 긍정으로 잘 예측한 비율을 무엇이라 하나요 ?
답: 민감도, 재현율
문제52. 긍정으로 예측한 비율에서 실제 긍정인 비율을 무엇이라 하나요 ?
답: 정밀도
문제53. 실제 부정인 범주중에 부정으로 잘 예측한 비율을 무엇이라 하나요 ?
답: 특이도
문제54. 그룹에 속한 사람들 간의 네트워크 특성과 구조를 분석하고 시각화하는 분석 기법을 무엇이라 하는가 ?
답: 사회 연결망 분석(SNA)
문제55. 어떤 주제에 대한 주관적인 인상, 감정, 태도, 개인의 의견들을 텍스트로 부터 뽑아내는 분석 방법을 무엇이라 하는가 ?
답: 감정분석
문제56. 주관적인 의견이 포함된 데이터에서 사용자가 게제한 의견과 감정을 나타내는 패턴을 분석하는 기법을 무엇이라 하는가?
답: 오피니언 마이닝
문제57. 텍스트 형태로 이루어진 비정형 데이터들을 자연어처리 방식을 이용하여 정보를 추출하는 기법을 무엇이라 하는가?
답: 텍스트 마이닝
문제58. 웹에서 발생하는 고객의 행위 분석과 특성 데이터를 추출, 정제하여 의사결정에 활용하기 위한 기법을 무엇이라 하는가?
답: 웹 마이닝
문제59. 모형의 평가지표가 우연히 나온 결과가 아니라는 것을 나타내는 지표가 무엇인가 ?
답: 카파 통계량
문제60. 가로축을 혼동행렬의 거짓 긍정률로 두고 세로축을 민감도로 두어 시각화한 그래프는 무엇인가 ?
답: ROC 곡선
문제61. 모델의 일반화 오차에 대해 신뢰할 만한 추정치를 구하기 위해 훈련 데이터의 일부를 평가 데이터로 하여 모델을 검증하는 기법을 무엇이라 하는가 ?
답: 교차검증
문제62. 가설검정에서 검정대상이 모집단의 평군이고 모집단의 수가 3개 이상일 때 사용하는 검정방법은 ?
답: ANOVA 분산분석
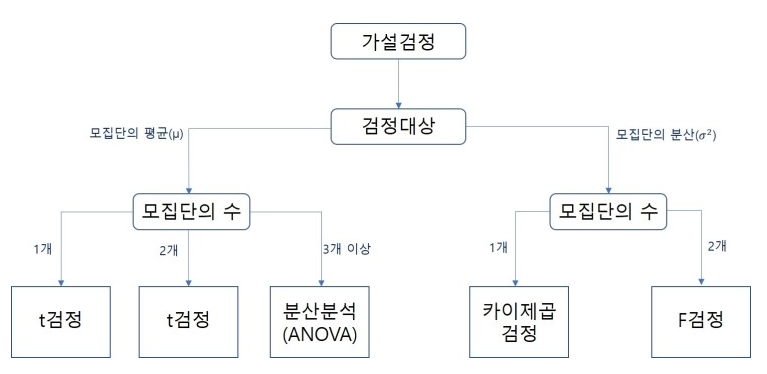
문제63. 가설검정에서 검정대상이 모집단 분산이고 모집단의 수가 2개일 때 사용하는 검정방법은 ?
답: F-검정
문제64. 귀무가설에서 검정 통계량의 분포를 정규 분포로 근사할 수 있는 통계 검정은 무엇인가 ?
답: Z-검정
문제65. 검정하는 통계량이 귀무가설 하에서 T-분포를 따르는 통계적 가설 검정으로 두 집단간의 평균을 비교하는 모수적 통계 방법으로서 표본이 정규성, 등분산성, 독립성들을 만족하는 경우에 적용하는 검정방법은?
답: T-검정
문제66. 동일한 확률분포를 가진 독립 확률 변수 n개의 평균분포는 n이 적당히 크다면 정규 분포에 가까워 지다는 이론은 무엇인가 ?
답: 중심극한정리
문제67. 두개 이상의 집단간 비교를 수행하고자 할 때 집단 내의 분산, 총 평균과 각 집단간의 평균 차이에 의해 생긴 집단 간 분산 비교로 얻은 F-분포를 이용하여 가설검정을 수행하는 방법은 무엇인가 ?
답: 분산분석
문제68. 관찰된 빈도가 기대되는 빈도와 유의미하게 다른지를 검정하기 위해 사용되며 단일 표본의 모집단이 정규분포를 따르며 분산을 알고 있는 경우에 적용하는 검정 방법은 무엇인가 ?
답: 카이제곱 검정
문제69. 두 표본의 분산에 대한 차이가 통계적으로 유의한가를 판별하는 검정 기법인데 두 모집단 분산 간의 비율에 대한 검정은 무엇인가 ?
답: F-검정
문제70. 연속 확률 분포의 하나로 일반적으로 발견되는 좌우대칭의 종 모양으로 생긴 분포를 무엇이라 하는가 ?
답: 정규분포
문제71. 귀무가설이 사실인데도 불구하고 사실이 아니라고 판정할 때 실제 확률을 나타내는 지표가 무엇인가 ?
답: p-값 , p-value
문제72. 인공신경망에서 관측된 값에서 연산된 값간의 차이를 연산하는 함수를 무엇이라 하는가 ?
답: 비용함수
문제73. 학습시에 인공신경망이 특정 뉴런 또는 특정 조합에 너무 의존적으로 되는것을 방지해주기 위해서 학습 과정에서 신경망의 일부를 사용하지 않는 방법을 무엇이라 하는가 ?
답: 드롭아웃
문제74. 여러개의 모델을 조화롭게 학습 시켜 그 모델들의 예측 결과들을 이용하여 더 정확한 예측값을 구하는 기법을 무엇이라 하는가 ?
답: 앙상블
문제75. 인공신경망에서 매개변수를 최적화하는 기법으로 기울기 방향으로 힘을 받으면 물체가 가속된다는 물리 법칙을 적용한 알고리즘이 무엇인가 ?
답: 모멘텀
문제76. 인공신경망에서 매개변수를 최적화하는 기법으로 손실함수의 기울기가 큰 첫 부분에서는 크게 학습하다가, 최적점에 가까워 질 수록 학습률을 줄여 조금씩 적게 학습하는 방식을 무엇이라 하는가?
답: Adagrade
문제77. 일반 pc 급 컴퓨터들로 가상화된 대형 스트로리지를 형성하고 그 안에 보관된 거대한 데이터 세트를 병렬로 처리할 수 있도록 개발된 오픈 소스 기반의 분산 컴퓨팅 플랫폼이 무엇인가?
답: 하둡
문제78. 관측된 데이터의 범위에서 많이 벗어난 아주 작은 값이나 아주 큰 값을 무엇이라 하는가 ?
답: 이상값(outlier)
문제79. 하나의 자산을 획득하려 할 때 주어진 기간 동안 모든 연관 비용을 고려할 수 있도록 확인하기 위해 사용하는 비즈니스 기여도 평가 기법은?
답: 총 소유 비용(TCO)
문제80. 자본 투자에 따른 순 효과의 비율을 의미하는 비즈니스 기여도 평가 기법은 ?
답: 투자대비효과(ROI)
문제81. 특정시점의 투자금액과 매출금액의 차이를 이자율을 고려하여 계산한 값이며 예상 투자비용의 할인가치를 예상수익의 할인 가치에서 공제했을때 나온 값을 합한 금액을 무엇이라 하는가?
답: 순현재가치(NPV)
문제82. 순 현재가치를 0 으로 만드는 할인율을 무엇이라 하는가 ?
답: 내부수익율(IRR)
문제83. 누계투자금액과 매출금액의 합이 같아지는 기간을 말하며 프로젝트 시작 시점부터 누적 현금흐름이 흑자로 돌아서는 시점까지의 기간을 무엇이라 하는가?
답: 투자 회수 기간
문제84. 사용자(분석자)가 특정 조건을 만족하거나 특정함수에 의해 값을 만들어 의미를 부여한 변수를 무엇이라 하는가?
답: 파생변수
문제85. 대규모로 저장된 데이터 안에서 체계적이고 자동으로 통계적 규칙이나 패턴을 찾아내는 기법을 무엇이라 하는가?
답: 데이터 마이닝
문제86. 주어진 자료에서 단순 랜덤 복원 추출 방법을 활용하여 동인한 크기의 표본을 여러개 생성하는 샘플링 방법을 무엇이라 하는가?
답: 부트스트랩
문제87. 귀무가설에서 검정 통계량의 분포를 정규 분포로 근사 할 수 있는 통계검정은 무엇인가?
답: Z-검정
문제88. 표본집단의 분포가 주어진 특정이론을 따르고 있는지를 검정하는 기법을 무엇이라 하는가?
답: 적합도 검정
문제89. 빅데이터 플렛폼의 데이터 형식으로 키-값 으로 이루어진 데이터 오브젝트를 전달하기 위해 텍스트를 사용하는 개방형 표준 포멧은 무엇인가 ?
답: JSON
문제90. 대용량 파일을 저장하고 처리하기 위해서 개발된 파일 시스템으로 네임노드와 데이터 노드로 구성된것은 ?
답: 하둡 분산 파일 시스템
문제91. 분석의 대상이 무엇인지 인지하고 있는 경우, 즉 해결해야할 문제를 알고 있고 이미 분석의 방법도 알고 있는 경우에 사용하는 분석 유형은 무엇인가 ?
답: 최적화
문제92. 해결해야할 문제는 알고 있지만 분석 방법을 모르는 경우에 사용하는 분석 유형은 무엇인가?
답: 솔루션, solution
문제93. 분석 방법은 알고있지만 분석 대상을 모르는 경우에 사용하는 분석 유형은 무엇인가?
답: 통찰
문제94. 분석 대상, 분석 방법 둘 다 모를 경우 사용하는 분석 유형은 무엇인가?
답: 발견
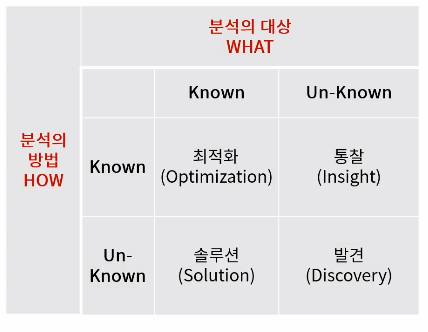
문제95. 두 변수가 키와 몸무게 , 수입과 지출등과 같은 수치적 데이터일 경우에 두 변수 사이의 연관성을 계량적으로 산출하여 분석하는 방법은 무엇인가 ?
답: 피어슨 상관계수
문제96. 표본으로부터 구한 통계량의 기대치가 추정하려 하는 모수의 실제 값에 같거나 가까워지는 성질을 무엇이라 하는가?
답: 불편성
문제97. 시계열 분석에서 시점에 상관없이 시계열의 특성이 일정하다는 것은 무엇인가 ?
답: 정상성
문제98. 두개 이상의 집단 간 비교를 수행하고자 할 때 집단 내의 분산, 총 평균과 각 집단의 평균 차이에 의해 생긴 집단 간 분산 비교로 얻은 F-분포를 이용하여 가설검정을 수행하는 방법을 무엇이라 하는가?
답: 분산 분석
문제99. 데이터를 0 을 중심으로 양쪽으로 데이터를 분포시키는 방법은 ?
답 : 표준화
문제100. 두 데이터의 비교를 위해 데이터를 0~1 사이의 실수로 분포시키는 방법을 무엇이라 하는가?
답: 정규화
'자격증' 카테고리의 다른 글
| [빅분기] 실기 작업형1 - 각종 메모 (0) | 2021.12.03 |
|---|---|
| [빅분기] 실기 작업형2- 분류 모델 (dataq 공식예제) (0) | 2021.12.02 |
| [빅분기] 실기 작업형2- 예측 모델 (프리렉 p445) (0) | 2021.12.02 |
| [빅분기] 빅분기 2회 실기 단답형 기출문제 (0) | 2021.11.24 |
| adsp, sqld, 정처기, 빅분기 시험 일정 정리 (0) | 2021.08.17 |